算法:树的两种搜索方式-深度优先 (DFS) & 广度优先 (BFS)
创建树 (Tree)
所有算法的实现都依赖对应的存储的数据结构,深度和广度的搜索其实也可以应用在图 (Graph)的数据结构。当然概念上树也是图一种。
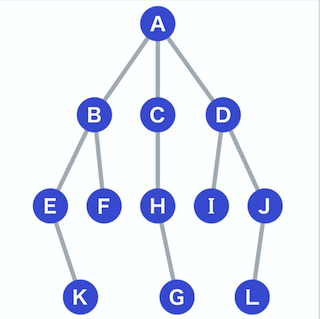
这里我们先把树 (tree) 数据结构创建好,然后再讲算法,下面的例子也会以此树为数据结构讲解。
{kind=link}
一个最简单树的节点包含几个关键信息:
Node {id, parentId, data}
id 为当前节点的标识,parentId为父节点的标识。 data 为绑定的数据。
线性存储结构:
[
{ id: 1, parentId: null, data: 'A' },
{ id: 2, parentId: 1, data: 'B' },
{ id: 3, parentId: 1, data: 'C' },
{ id: 4, parentId: 1, data: 'D' },
{ id: 5, parentId: 2, data: 'E' },
{ id: 6, parentId: 2, data: 'F' },
{ id: 7, parentId: 8, data: 'G' },
{ id: 8, parentId: 3, data: 'H' },
{ id: 9, parentId: 4, data: 'I' },
{ id: 10, parentId: 4, data: 'J' },
{ id: 11, parentId: 5, data: 'K' },
{ id: 12, parentId: 10, data: 'L' },
]
虽然这是一种树的存储结构,但在节点的查找、添加、删除上并不那么高效,实际应用更多的是引用的存储结构。
引用存储的结构:
{
id: 1,
parentId: null,
data: 'A',
children: [
{
id: 2,
parentId: 1,
data: 'B',
children: [
{
id: 5,
parentId: 2,
data: 'E',
children: [
{ id: 11, parentId: 5, data:'K'}
]
}
{ id: 6, parentId: 2, data: 'F'}
]
},
{
id: 3,
parentId: 1,
data: 'C',
children: [...],
},
...
],
};
为了初始化引用结构,我们可以把线性结构转化为树结构:
// 创建 id 和索引的映射
const idMapping = data.reduce((acc, el, i) => {
acc[el.id] = i;
return acc;
}, {});
let root;
data.forEach(el => {
// 处理根元素
if (el.parentId === null) {
root = el;
return;
}
// 获取父元素
const parentEl = data[idMapping[el.parentId]];
// 把当前元素添加到父元素的 children 数组里去。
parentEl.children = [...(parentEl.children || []), el];
});
转化的思路是线性遍历 data,通过 idMapping 找到当前节点的父节点,然后往父节点的 children 添加 当前节点。当遍历完成,所有数据也就添加完毕。
深度优先 (DFS)
Depth First Search,深度优先的搜索在遍历节点时,假如同时存在兄弟节点和子节点,它会优先查找子节点。
动画
在树里找到 G 这个节点,需要如下遍历流程:
{kind=link}
解读步骤
- A 作为
起点,G 作为目标开始搜索; - 从 A 可以到达的点有 B、C 和 D,他们将作为下一个目标的候选点;
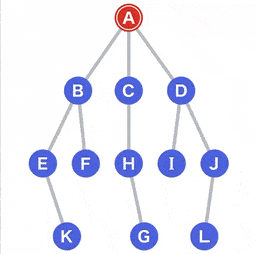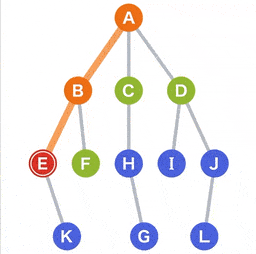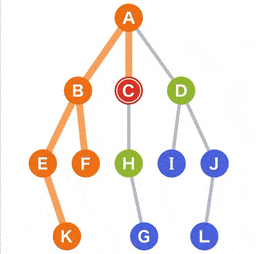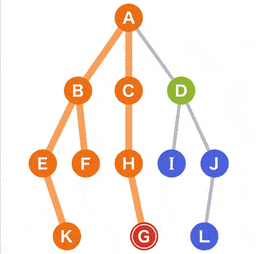
- 从候选中选择一个点。对于选择标准,选择最新被添加到候选中的候选点。当有多个候选点时,可以选择其中任何一个。为了方便,这次将从左侧的点选择;
- 这次由于所有的点都在同时成为候选,我们选择 B,移动到选定的 B;
- 从当前 B 可以到达的点 E 和 F 被添加为新的候选;
- 选择点在
先进后出 (LIFO)的方法下管理,因此我们可以使用堆栈的数据结构; - 在候选中,E 和 F 是最近添加的。我们选择左边的 E,移动到选定的 E;
- 从当前的点 E 可以到达的点 K 被添加为新的候选;
- 下面,重复相同的操作,直到到达目标或者搜索完所有点;
具体实现
function DFS(tree, targetValue) {
let collection = [tree];
while (collection.length) {
let node = collection.shift();
if(node.data === targetValue) return node;
collection.unshift(...node.children);
}
return null;
}
广度优先 (BFS)
Breadth First Search,广度优先的搜索在遍历节点时,假如同时存在兄弟节点和子节点,它会优先查找兄弟节点。
动画
在树里找到 G 这个节点,需要如下遍历流程:
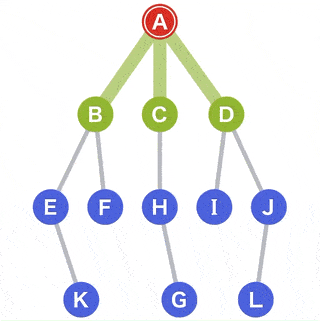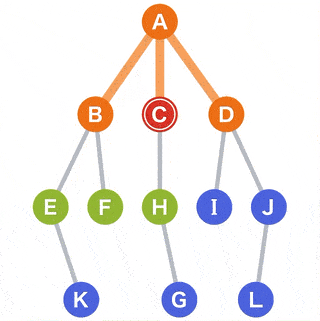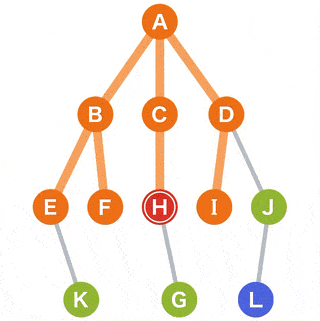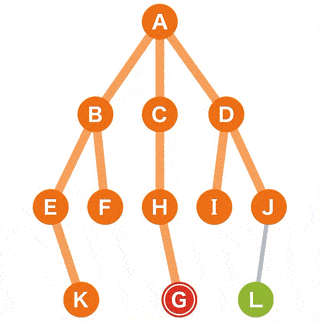{kind=link}
解读步骤
- A 作为
起点,G 作为目标开始搜索; - 从 A 可以到达的点有 B、C 和 D,他们将作为下一个目标的候选点;
- 从候选中选择一个点。对于选择标准,选择最新被添加到候选中的候选点。当有多个候选点时,可以选择其中任何一个。为了方便,这次将从左侧的点选择;
- 这次由于所有的点都在同时成为候选,我们选择 B,移动到选定的 B;
- 从当前 B 可以到达的点 E 和 F 被添加为新的候选;
- 选择点在
先进先出 (FIFO)的方法下管理,因此我们可以使用队列的数据结构; - 在候选中,C 和 D 是最早添加的。我们选择左边的 C,移动到选定的 C;
- 从当前点 C 可以到达的点 H 被添加为新的候选;
- 下面,重复相同的操作,直到到达目标或者搜索完所有点;
具体实现
function BFS(tree, targetValue) {
let collection = [tree];
while (collection.length) {
let node = collection.shift();
if(node.data === targetValue) return node;
collection.push(...node.children);
}
return null;
}
深度优先 vs 广度优先
一棵树,假如深度值 (depth level) 比较大,通常采用深度优先的搜索方法。
在 React 中,如果节点组件状态发生变化的时,会采用深度优先的策略。以当前节点作为起始点,搜索所有受影响的子节点。
在 React 16 后,官方做了优化,不再只是使用深度优先算法去做简单的 Diff 操作,而采用任务时间分片的方式,这种方法被叫做 Fiber。可以参考:Fiber 如何解决 React 中动画掉帧问题
而在深度相对小,树的横向枝叶比较多的时候,就可以考虑广度优先。